Audio Annotation

Speech Recognition
Speech Recognition technology converts spoken language into text by analysing and interpreting audio signals. This capability is essential for a variety of applications, including virtual assistants, transcription services, and voice-controlled interfaces. Our advanced speech recognition solutions provide accurate and real-time transcriptions, enabling seamless interactions and efficient data processing. With our cutting-edge algorithms, your AI systems can understand, and process spoken language with high accuracy, enhancing user experiences and operational efficiency.
Emotion Recognition
Emotion Recognition in audio involves identifying and interpreting the emotional tone conveyed in speech. This technology is crucial for customer service, mental health applications, and social media analysis, where understanding the speaker’s emotions can provide valuable insights. Our emotion recognition services utilize sophisticated algorithms to detect emotions such as happiness, sadness, anger, and surprise in audio recordings. By integrating our solutions, you can enhance your AI system’s ability to respond empathetically and appropriately to human emotions.

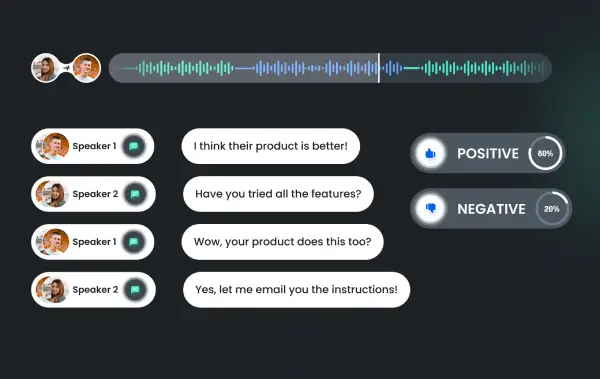
Speaker Identification
Speaker Identification technology distinguishes and recognizes individual speakers within an audio stream. This capability is vital for applications such as security, personalized user experiences, and multi-speaker environments. Our speaker identification solutions deliver accurate and reliable results, even in noisy or complex audio environments. By leveraging our technology, you can enhance your systems’ ability to identify and authenticate speakers, ensuring personalized and secure interactions.
Named Entity Recognition (NER) in Audio
Named Entity Recognition (NER) in audio involves identifying and classifying key entities mentioned in spoken language, such as names of people, organizations, locations, dates, and more. This technology is essential for extracting meaningful information from audio data in applications like automated transcriptions, voice-activated search, and business intelligence. Our NER in audio solutions provides precise and context-aware entity extraction, enabling your AI systems to understand and utilize spoken content effectively.

Audio Tagging and Transcription
Audio Tagging and Transcription services involve labelling and converting audio content into text. This process is crucial for organizing, searching, and analysing audio data. Our comprehensive audio tagging and transcription services provide accurate, high-quality transcriptions and relevant tags for various audio types, including interviews, podcasts, and customer calls. By using our services, you can ensure your audio data is accessible, searchable, and ready for analysis, enhancing your content management and data utilization capabilities.
Language and Dialect Identification
Language and Dialect Identification technology detects the language and specific dialect spoken in an audio recording. This capability is important for multilingual applications, translation services, and targeted marketing. Our language and dialect identification solutions offer accurate and fast detection, supporting a wide range of languages and regional dialects. With our expertise, your AI systems can handle diverse linguistic inputs, providing more inclusive and globally aware services.
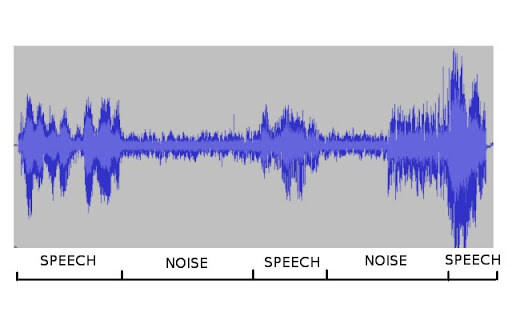
Voice Activity Detection (VAD)
Voice Activity Detection (VAD) technology distinguishes between speech and non-speech segments in audio recordings. This functionality is essential for improving the performance of speech recognition systems, telecommunication applications, and audio surveillance. Our VAD solutions provide precise and reliable detection of voice activity, even in challenging acoustic environments. By integrating our VAD technology, you can enhance the efficiency and accuracy of your audio processing systems, ensuring they focus on relevant speech segments.